Vignette: A spatial simulation#
Here we’ll talk through a typical workflow with pyslim, which will:
Simulate data with SLiM, remembering some ancestral individuals.
Recapitate and mutate.
Take a subsample of the modern and ancestral individuals.
Get these individual locations and make a map.
Compute divergences between individuals, and plot against geographic distance.
Write out a VCF file of these individuals’ genotypes and other data for use by other programs.
Simulation#
Here is a simple spatial SLiM recipe that simulates 1000 individuals on a spatial landscape. The focus of this vignette is not on SLiM, so we won’t go into detail here. Here are notes:
It does not have any mutations: we’ll add these on afterwards.
There is local fecundity regulation of population density: individuals with more neighbors have fewer offspring.
We run the simulation for 2000 time steps, and “remember” everyone who is alive at time step 1000.
initialize() {
initializeSLiMModelType("nonWF");
initializeSLiMOptions(dimensionality="xy");
initializeTreeSeq();
initializeMutationRate(0.0);
initializeMutationType("m1", 0.5, "f", 0.0);
initializeGenomicElementType("g1", m1, 1.0);
initializeGenomicElement(g1, 0, 1e8-1);
initializeRecombinationRate(1e-8);
defineConstant("LAMBDA", 2.0); // birth rate
defineConstant("K", 1); // carrying capacity per unit area
defineConstant("W", 35); // width and height of the area
defineConstant("MU", 0.5); // death rate
defineConstant("SIGMA", 1.0); // interaction distance
// spatial interaction for local competition
initializeInteractionType("i1", "xy", reciprocal=T,
maxDistance = 3 * SIGMA);
i1.setInteractionFunction("n", 1.0/(2*PI*SIGMA^2), SIGMA);
}
reproduction() {
neighbor_density = i1.localPopulationDensity(individual);
num_offspring = rpois(1, LAMBDA / (1 + neighbor_density / K));
mate = i1.drawByStrength(individual, 1); // single mating
if (size(mate) > 0) {
for (k in seqLen(num_offspring)) {
offspring = p1.addCrossed(individual, mate);
pos = individual.spatialPosition + rnorm(2, 0, SIGMA);
offspring.setSpatialPosition(p1.pointReflected(pos));
}
}
}
1 early() {
sim.addSubpop("p1", K * W * W);
p1.setSpatialBounds(c(0.0, 0.0, W, W));
for (ind in p1.individuals) {
ind.setSpatialPosition(p1.pointUniform());
}
}
early() { // survival probabilities
p1.fitnessScaling = 1 - MU;
}
late() {
i1.evaluate(sim.subpopulations);
}
1000 late() {
sim.treeSeqRememberIndividuals(p1.individuals);
}
2000 late() {
sim.treeSeqOutput("spatial_sim.trees");
catn("Done.");
sim.simulationFinished();
}
%%bash
slim -s 23 vignette_space.slim
// Initial random seed:
23
// RunInitializeCallbacks():
initializeSLiMModelType(modelType = 'nonWF');
initializeSLiMOptions(dimensionality = 'xy');
initiali
zeTreeSeq();
initializeMutationRate(0);
initializeMutationType(1, 0.5, "f", 0);
initializeGenomicElementType(1, m
1, 1);
initializeGenomicElement(g1, 0, 99999999);
initializeRecombinationRate(1e-08);
initializeInte
ractionType(1, "xy", reciprocal=T, maxDistance=3);
// Starting run at tick <start>:
1
Done.
Ok, now let’s have a quick look at the output:
import tskit
slim_ts = tskit.load("spatial_sim.trees")
print(f"The tree sequence has {slim_ts.num_trees} trees\n"
f"on a genome of length {slim_ts.sequence_length},\n"
f"{slim_ts.num_individuals} individuals, {slim_ts.num_samples} 'sample' genomes,\n"
f"and {slim_ts.num_mutations} mutations.")
The tree sequence has 27846 trees
on a genome of length 100000000.0,
1965 individuals, 3930 'sample' genomes,
and 0 mutations.
It makes sense we have no mutations: we haven’t added any yet. The tree sequence is recording the relationship between 5,424 genomes (the “samples”), which requires 37,095 distinct trees along the genome. Individuals are diploid, which explains why the number of individuals is equal to half the number of samples. Let’s have a look at how old those individuals are, by tabulating when they were born:
import numpy as np
individual_times = slim_ts.individuals_time
for t in np.unique(individual_times):
print(f"There are {np.sum(individual_times == t)} individuals from time {t}.")
There are 556 individuals from time 0.0.
There are 250 individuals from time 1.0.
There are 153 individuals from time 2.0.
There are 71 individuals from time 3.0.
There are 32 individuals from time 4.0.
There are 10 individuals from time 5.0.
There are 8 individuals from time 6.0.
There are 2 individuals from time 7.0.
There are 3 individuals from time 8.0.
There are 1 individuals from time 9.0.
There are 414 individuals from time 1000.0.
There are 224 individuals from time 1001.0.
There are 126 individuals from time 1002.0.
There are 59 individuals from time 1003.0.
There are 28 individuals from time 1004.0.
There are 19 individuals from time 1005.0.
There are 5 individuals from time 1006.0.
There are 2 individuals from time 1007.0.
There are 1 individuals from time 1008.0.
There are 1 individuals from time 1009.0.
These “times” record the birth times of each individual. These are tskit times, which are in units of “time ago”, so for instance, there are 343 individuals born one time unit before the end of the simulation and 167 born two time units before the end of the simulation. (This confusing choice of units is because tskit was developed for msprime, a coalescent simulator.) This also tells us that there’s a bunch of individuals born around 1000 time steps ago, when we asked SLiM to Remember everyone alive at the time, and some more in the past few time steps, i.e., the present. This is a non-Wright-Fisher simulation, and so individuals may live for more than one time step (even up to age 10, it seems). Let’s check that all these individuals are alive at either (a) today or (b) 1000 time steps ago.
for t in [0, 1000]:
alive = pyslim.individuals_alive_at(slim_ts, t)
print(f"There were {len(alive)} individuals alive {t} time steps in the past.")
There were 1086 individuals alive 0 time steps in the past.
There were 879 individuals alive 1000 time steps in the past.
And, 1242 + 1255 is 2497, the total number of individuals. So, this all checks out.
Recapitation and mutation#
Next, we want to (a) simulate some ancestral diversity and (b) add in neutral mutations. Please see Haller et al (2019) for the why and how of these steps. But, first let’s see if recapitation is necessary: on how much of the genome is the tree sequence not coalesced? In other words, recapitation adds diversity present in the initial generation; will it make a difference? In fact, no segments of the genome have coalesced:
print(f"Number of trees with only one root: {sum([t.num_roots == 1 for t in slim_ts.trees()])}\n"
f"Number with more than one root: {sum([t.num_roots > 0 for t in slim_ts.trees()])}")
Number of trees with only one root: 0
Number with more than one root: 27846
Next, we will:
Recapitate, running a coalescent simulation to build ancestral trees.
Mutate, adding neutral variation.
Save the resulting tree sequence to disk for future use.
We won’t simplify, since we may as well keep around all the information.
But, if we did (e.g., if we were running a large number of simulations),
we would need to pass keep_input_roots=True to allow recapitation.
Note
The units of time in the tree sequence are SLiM’s “time steps”, and so are not necessarily equal to the mean generation time in a non-Wright-Fisher model. Per-generation rates need to be divided by the mean generation time, which can be measured in SLiM.
recap_ts = pyslim.recapitate(slim_ts, recombination_rate=1e-8, ancestral_Ne=1000)
ts = msprime.sim_mutations(
recap_ts,
rate=1e-8,
model=msprime.SLiMMutationModel(type=0),
keep=True,
)
ts.dump("spatial_sim.recap.trees")
print(f"The tree sequence now has {ts.num_trees} trees,\n"
f" and {ts.num_mutations} mutations.")
/home/runner/work/tskit-site/tskit-site/.venv/lib/python3.12/site-packages/msprime/ancestry.py:1290: TimeUnitsMismatchWarning: The initial_state has time_units=ticks but time is measured in generations in msprime. This may lead to significant discrepancies between the timescales. If you wish to suppress this warning, you can use, e.g., warnings.simplefilter('ignore', msprime.TimeUnitsMismatchWarning)
sim = _parse_sim_ancestry(
The tree sequence now has 34516 trees,
and 72137 mutations.
See Adding neutral mutations to a SLiM simulation for discussion of the options to
msprime.sim_mutations().
We will have no further use for slim_ts or for recap_ts;
we’ve just given them separate names for tidyness.
And, since the original SLiM mutation had no mutations, we didn’t need to specify keep=True
in sim_mutations, but if we had put down selected mutations with SLiM
we’d probably want to keep them around.
Take a sample of individuals#
Now it’s time to compute some things. In real life we don’t get to work with everyone usually, so we’ll take a subset of individuals. The range we have simulated has width and height 35 units, with a population density of around 1 per unit area. We’ll get genomes to work with by pulling out
All the modern individuals in the five squares of width 5 in the corners of the range and the center, and
Five individuals sampled randomly from everyone alive 1000 time steps ago.
np.random.seed(23)
alive = pyslim.individuals_alive_at(ts, 0)
locs = ts.individuals_location[alive, :]
W = 35
w = 5
groups = {
'topleft' : alive[np.logical_and(locs[:, 0] < w, locs[:, 1] < w)],
'topright' : alive[np.logical_and(locs[:, 0] < w, locs[:, 1] > W - w)],
'bottomleft' : alive[np.logical_and(locs[:, 0] > W - w, locs[:, 1] < w)],
'bottomright' : alive[np.logical_and(locs[:, 0] > W - w, locs[:, 1] > W - w)],
'center' : alive[np.logical_and(np.abs(locs[:, 0] - W/2) < w/2,
np.abs(locs[:, 1] - W/2) < w/2)]
}
old_ones = pyslim.individuals_alive_at(ts, 1000)
groups['ancient'] = np.random.choice(old_ones, size=5)
for k in groups:
print(f"We have {len(groups[k])} individuals in the {k} group.")
We have 28 individuals in the topleft group.
We have 15 individuals in the topright group.
We have 22 individuals in the bottomleft group.
We have 12 individuals in the bottomright group.
We have 31 individuals in the center group.
We have 5 individuals in the ancient group.
To keep names associated with each subset of individuals,
we’ve kept the individuals in a dict, so that for instance
groups["topleft"] is an array of all the individual IDs that are in the top left corner.
The IDs of the ancient individuals we will work with are kept in the array ancient.
Let’s do a quick consistency check, that everyone in ancient was actually born around 1000 time steps ago:
for i in groups["ancient"]:
ind = ts.individual(i)
# TODO: will work on next tskit release
# assert(ind.time >= 1000 and ind.time < 1020)
time = ts.node(ind.nodes[0]).time
assert(time >= 1000 and time < 1020)
No errors occurred, so that checks out.
Plotting locations#
We should check this: plot where these individuals lie
relative to everyone else.
The individuals locations are available as a property of individuals,
but to make things easier, it’s also present in a num_individuals x 3
numpy array as ts.individuals_location.
(There are three columns because SLiM allows for
(x, y, z) coordinates, but we’ll just use the first two.)
Since groups["topleft"] is an array of individual IDs,
we can pull out the locations of the “topleft” individuals
by indexing the rows of the individual location array:
print("Locations:")
all_locs = ts.individuals_location
print(all_locs)
print("shape:")
all_locs.shape
print("topleft locations shape:")
all_locs[groups["topleft"], :].shape
Locations:
[[ 2.03728539 10.18936316 0. ]
[30.17518129 5.7038621 0. ]
[ 7.48606376 27.65855549 0. ]
...
[30.81022541 10.0346995 0. ]
[18.4204526 0.71951241 0. ]
[15.9421442 33.07851405 0. ]]
shape:
topleft locations shape:
(28, 3)
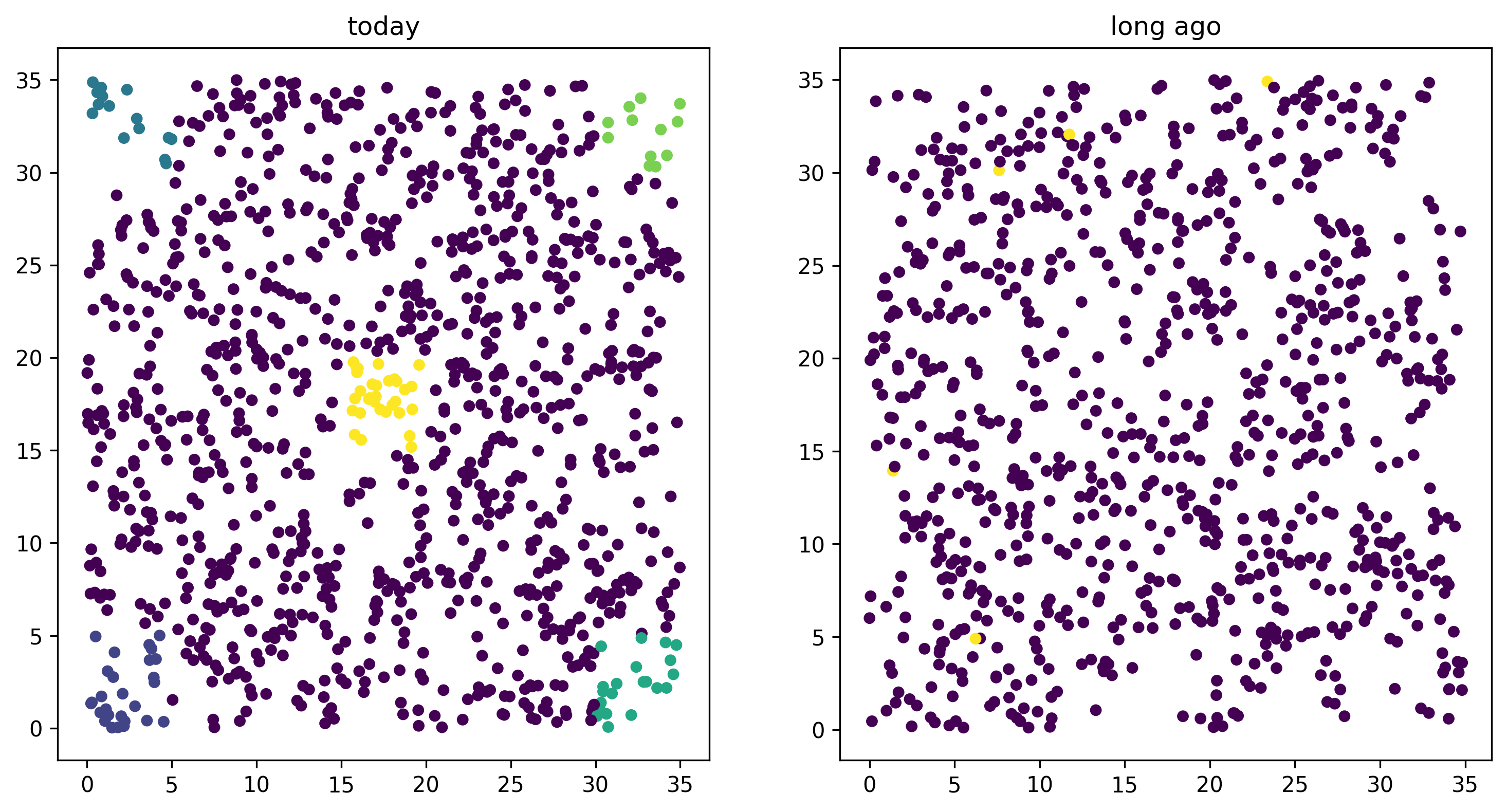
Using this, we can easily plot the locations of all the individuals from today (on the left) and 1000 time steps ago (on the right). We have to do a bit of mucking around to set the colors so that they reflect which group each individual is in.
import matplotlib
import matplotlib.pyplot as plt
group_order = ['topleft', 'topright', 'bottomleft', 'bottomright', 'center', 'ancient']
ind_colors = np.repeat(0, ts.num_individuals)
for j, k in enumerate(group_order):
ind_colors[groups[k]] = 1 + j
old_locs = ts.individuals_location[old_ones, :]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6), dpi=300)
ax1.set_title("today")
ax1.scatter(locs[:,0], locs[:,1], s=20, c=ind_colors[alive])
ax2.set_title("long ago")
ax2.scatter(old_locs[:, 0], old_locs[:, 1], s=20, c=ind_colors[old_ones]);
Isolation by distance#
Now, let’s look at isolation by distance, i.e., let’s compare geographic and genetic distances. Here, “genetic distance” will be mean pairwise sequence divergence. First, we’ll compute mean genetic distance between each of our five groups.
The first thing we need to do is some bookkeeping. So far, we’ve just worked with individuals, but tree sequence tools, in particular the statistics computation methods from tskit, are designed to work with genomes, also known as “nodes”. So, first we need to pull out the node IDs corresponding to the individuals we want. The things that make up a tree sequence - individuals, nodes, mutations, etcetera - can generally be examined individually. For instance, here’s what we have for the the first “ancient” individual:
print(ts.individual(groups['ancient'][0]))
Individual(id=np.int64(1681), flags=131072, location=array([11.74309795, 32.05890993, 0. ]), parents=array([-1, -1], dtype=int32), nodes=array([8052, 8053], dtype=int32), metadata={
'pedigree_id': 961907,
'pedigree_p1': 960316,
'pedigree_p2': 961387,
'age': 0,
'subpopulation': 1,
'sex': -1,
'flags': 0
})
Notice that among other things, each individual carries around a list of their node IDs, i.e., their genomes. We need to put these all in a list of lists, so that, for instance, the first element of the list will have the node IDs of all the genomes of the individuals in the “topleft” group. And, since we kept the individual IDs in a dict, which are unordered, we’ll have to do some extra work to make sure we keep track of order.
sampled_nodes = [[] for _ in groups]
for j, k in enumerate(group_order):
for ind in groups[k]:
sampled_nodes[j].extend(ts.individual(ind).nodes)
Let’s do a consistency check: the number of nodes in each element of this list should be twice the number of individuals in the corresponding list.
print([len(groups[k]) for k in groups])
print([len(u) for u in sampled_nodes])
[28, 15, 22, 12, 31, 5]
[56, 30, 44, 24, 62, 10]
For instance, in the ‘topleft’ corner there are 12 diploids, with 24 nodes. That checks out.
Now, we can compute the matrix of pairwise mean sequence divergences
between and within these sets.
This is done using the ts.divergence method.
pairs = [(i, j) for i in range(6) for j in range(6)]
group_div = ts.divergence(sampled_nodes, indexes=pairs).reshape((6, 6))
print("\t" + "\t".join(group_order))
for i, group in enumerate(group_order):
print(f"{group_order[i]}:\t" + "\t".join(map(str, np.round(group_div[i], 7))))
topleft topright bottomleft bottomright center ancient
topleft: 2.06e-05 5.3e-05 4.74e-05 5.31e-05 4.93e-05 5.49e-05
topright: 5.3e-05 2.12e-05 5.48e-05 5.4e-05 5.19e-05 5.49e-05
bottomleft: 4.74e-05 5.48e-05 3.33e-05 5.13e-05 5.08e-05 5.55e-05
bottomright: 5.31e-05 5.4e-05 5.13e-05 3.36e-05 5.05e-05 5.59e-05
center: 4.93e-05 5.19e-05 5.08e-05 5.05e-05 4.35e-05 5.49e-05
ancient: 5.49e-05 5.49e-05 5.55e-05 5.59e-05 5.49e-05 4.11e-05
That’s nice, but to look at isolation by distance, we should actually separate out the individuals. To do that, we need to create a list of lists of nodes whose j-th entry is the nodes belonging to the j-th individual, and to keep track of which group each one belongs to.
ind_nodes = []
ind_group = []
ind_ids = []
for j, group in enumerate(group_order):
for ind in groups[group]:
ind_ids.append(ind)
ind_nodes.append(ts.individual(ind).nodes)
ind_group.append(group_order[j])
nind = len(ind_ids)
pairs = [(i, j) for i in range(nind) for j in range(i, nind)]
ind_div = ts.divergence(ind_nodes, indexes=pairs)
Here we’ve only computed divergences in the upper triangle of the pairwise divergence matrix, with heterozygosities on the diagonal. We’ll also need pairwise geographic distances:
geog_dist = np.repeat(0.0, len(pairs))
locs = ts.individuals_location
for k, (i, j) in enumerate(pairs):
geog_dist[k] = np.sqrt(np.sum(
(locs[ind_ids[i], :2]
- locs[ind_ids[j], :2])**2
))
Let’s check that makes sense: distances of individuals from themselves should be zero.
for (i, j), x in zip(pairs, geog_dist):
if i == j:
assert(x == 0)
Python does not complain, which is good. Now let’s plot genetic distance against geographic distance.
pair_colors = np.repeat(0, len(pairs))
for k, (i, j) in enumerate(pairs):
if ind_group[i] == "ancient" or ind_group[j] == "ancient":
pair_colors[k] = 1
fig = plt.figure(figsize=(6, 6), dpi=300)
ax = fig.add_subplot(111)
ax.scatter(geog_dist, 1e3 * ind_div, s=20, alpha=0.5,
c=pair_colors)
ax.set_xlabel("geographic distance")
ax.set_ylabel("genetic distance (diffs/Kb)");
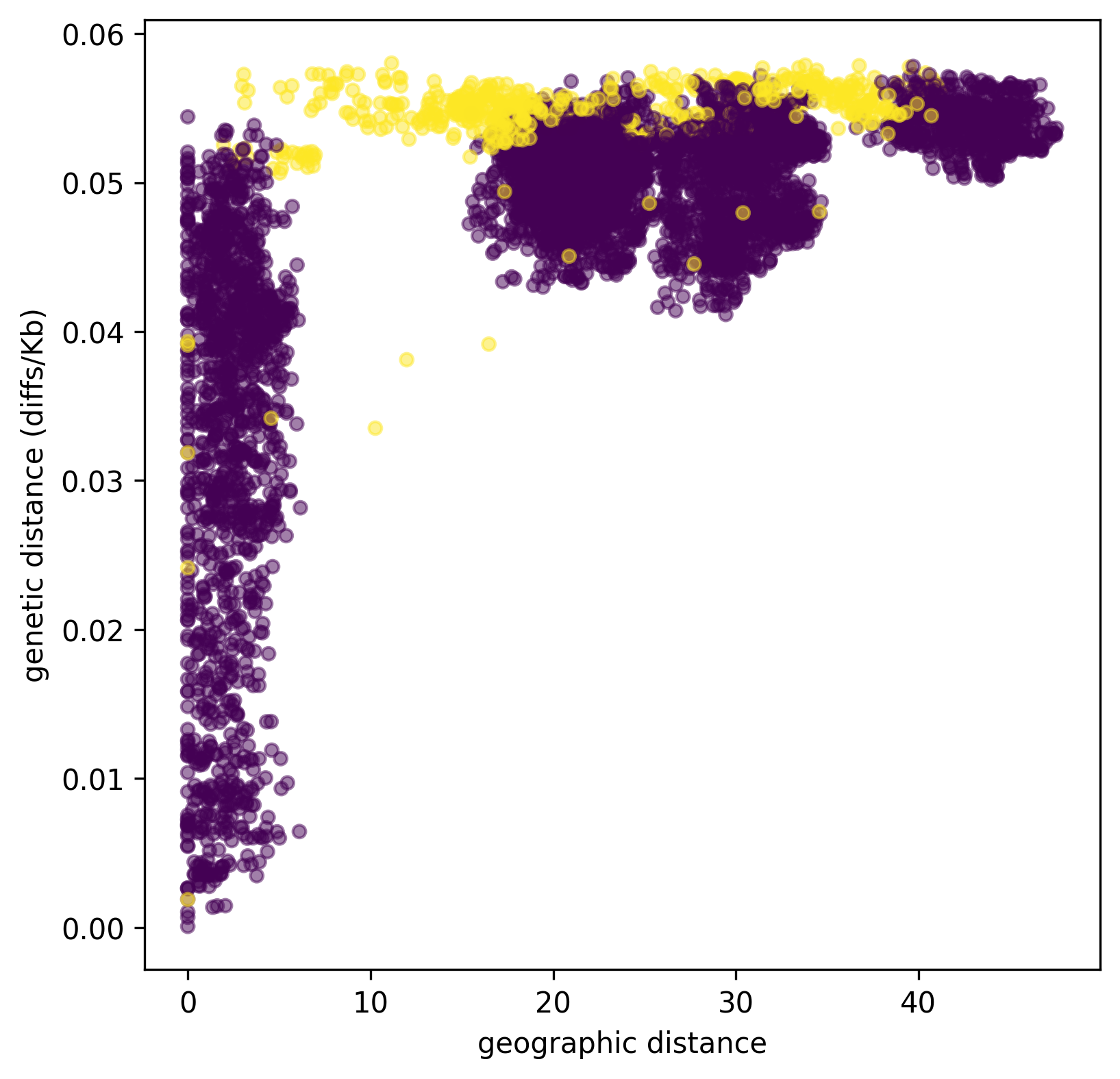
Since we multiplied ind_div by 1,000,
the units of genetic distance are in mean number of nucleotide differences per kilobase.
It is clear that closer samples are more closely related,
and the distinct clusters corresponding to the five sampled boxes are visible.
Furthermore, ancient samples are generally more distantly diverged.
VCF output#
Now we want to write out these data for analysis with other programs. To do this, and make sure that everything stays nicely cross-referenced, we’re going to loop through the sampled individuals, writing their information to a file, while at the same time constructing a list of individual IDs, whose genomes we will write out to a VCF file.
indivlist = []
indivnames = []
with open("spatial_sim_individuals.txt", "w") as indfile:
indfile.writelines("\t".join(["vcf_label", "tskit_id", "slim_id"]
+ ["birth_time_ago", "age", "x", "y"]) + "\n")
for group in group_order:
for i in groups[group]:
indivlist.append(i)
ind = ts.individual(i)
vcf_label = f"tsk_{ind.id}"
indivnames.append(vcf_label)
time = ts.node(ind.nodes[0]).time
data = [vcf_label, str(ind.id), str(ind.metadata["pedigree_id"]), str(time),
str(ind.metadata["age"]), str(ind.location[0]), str(ind.location[1])]
indfile.writelines("\t".join(data) + "\n")
with open("spatial_sim_genotypes.vcf", "w") as vcffile:
ts.write_vcf(vcffile, individuals=indivlist, individual_names=indivnames)
More information#
The distinction between “nodes” (i.e., genomes) and “individuals” can be confusing, as well as the idea of “samples”. Please see the the tskit data model for more explanation about these concepts.
The general interface for computing statistics (explaining, for instance, the “indexes” argument above) is described in the tskit documentation also.
What about simplification?#
The tree sequence we worked with here contains more information than we need,
including the first generation individuals.
If we wanted to remove this, we could have used the
simplify method,
which reduced the tree sequence to the minimal required to record the information
about a provided set of nodes.
In the workflow above we didn’t ever simplify the tree sequence,
because we didn’t need to.
Because simplify reorders nodes and removes unused individuals and populations,
it requires an extra layer of bookkeeping.
Such relabeling also makes it harder to compare results across different analyses
of the same data.
Simplifying the tree sequence down to the nodes of the individuals in our “groups” would not change any subsequent analysis (except perhaps removing monomorphic sites in the VCF output), and would speed up computation of diversity. Since the calculation was fast already, it wasn’t worth it in this case, but for much larger tree sequences it could be worth the extra code complexity.