Mutation simulations#
Ancestry simulations in msprime simulate a random
ancestral history of a set of sampled genomes. While the trees representing
this history are very useful (and often all we need, for many purposes),
they do not include any information about what the actual genome sequences
would look like for these samples. To produce genetic variation data
(as represented by a VCF file,
for example), we need to simulate some extra information: we need
mutations. Msprime provides a powerful and efficient way of superimposing
neutral mutations from a range of sequence evolution
models using the sim_mutations()
function.
For example, here we simulate the ancestry of two diploids (and therefore
four sample genomes) and store the resulting tskit.TreeSequence
object in the ts variable. We then simulate some mutations on
that tree sequence, and show the resulting tree with mutations:
ts = msprime.sim_ancestry(2, sequence_length=100, random_seed=1234)
mts = msprime.sim_mutations(ts, rate=0.01, random_seed=5678)
SVG(mts.draw_svg())

We can see the variation data produced by these mutations most simply
via the tskit.TreeSequence.variants() method:
for var in mts.variants():
print(var.site.position, var.alleles, var.genotypes, sep="\t")
7.0 ('T', 'G') [0 1 1 0]
8.0 ('A', 'T') [0 1 1 0]
18.0 ('T', 'A') [0 1 1 0]
19.0 ('A', 'C') [0 1 1 0]
28.0 ('C', 'G') [0 1 1 0]
41.0 ('T', 'C') [1 0 0 1]
55.0 ('T', 'G') [0 0 0 1]
73.0 ('A', 'C') [0 1 1 0]
78.0 ('C', 'G') [1 0 0 1]
79.0 ('G', 'T') [1 0 0 1]
The tskit library has many powerful methods for working with mutation data — see the Getting started with tskit tutorial for more information.
Quick reference#
sim_mutations()Add simulated mutations to a tree sequence
Models
JC69(Nucleotides)Jukes & Cantor model (‘69), equal probability of transitions between nucleotides
HKY(Nucleotides)Hasegawa, Kishino & Yano model (‘85), different probabilities for transitions and transversions
F84(Nucleotides)Felsenstein model (‘84), different probabilities for transitions and transversions
GTR(Nucleotides)Generalised Time-Reversible nucleotide mutation model
BLOSUM62(Amino acids)The BLOSUM62 model of time-reversible amino acid mutation
PAM(Amino acids)The PAM model of time-reversible amino acid mutation
BinaryMutationModel(Binary ancestral/derived)Binary mutation model with two flip-flopping alleles: “0” and “1”.
SMM(Microsatellites)Stepwise mutation model for microsatellites
TPM(Microsatellites)Equal rate, two-phase model for microsatellites
EL2(Microsatellites)Equal rate, two-phase, linear bias model for microsatellites
InfiniteAlleles(Integers)A generic infinite-alleles mutation model
SLiMMutationModel(Integers)An infinite-alleles model producing SLiM-style mutations
MatrixMutationModel(General finite state model)Superclass of mutation models with a finite set of states
Specifying rates#
The rate parameter of sim_mutations() determines the rate of mutations per unit
of sequence length per generation. A rate must be specified for mutations to be generated.
ts = msprime.sim_ancestry(2, random_seed=1)
mts = msprime.sim_mutations(ts, rate=1, random_seed=1)
mts.num_mutations
7
Running sim_mutations() on this simulated tree of length 1 with rate=1
produces 7 mutations.
Specifying higher rates lead to proportionately more mutations:
ts = msprime.sim_ancestry(2, random_seed=1)
mts = msprime.sim_mutations(ts, rate=5, random_seed=1)
mts.num_mutations
32
It’s also possible to provide a RateMap which specifies variable
mutation rates over different stretches of the sequence.
In the following example, the mutation rate between positions 0 and 2 is 0.5, between positions 2 and 5 is 0, and between positions 5 and 10 is 0.1:
ts = msprime.sim_ancestry(4, sequence_length=7, random_seed=1)
ratemap = msprime.RateMap(position=[0, 2, 5, 7], rate=[0.5, 0, 0.1])
mts = msprime.sim_mutations(ts, rate=ratemap, random_seed=10)
SVG(mts.draw_svg(node_labels={}, size=(400, 300)))

As we can see from the output, there are three mutations at site 0 (position 0), three mutations at site 1 (position 1), no mutations between positions 2 and 5 (where the mutation rate is zero) and one mutation at site 2 (position 5). This illustrates that as the rate increases, the probability of recurrent mutation (multiple mutations at a site) also increases.
Note
If using a RateMap with sim_mutations(), be sure that the final
position of the RateMap is the same as the
sequence_length of the tree sequence you’re adding mutations to!
Discrete or continuous#
As in sim_ancestry() (see Discrete or continuous?),
the discrete_genome parameter controls whether mutations should be placed at
discrete, integer coordinates or continuously at floating point positions.
discrete_genome=True is the default:
ts = msprime.sim_ancestry(4, sequence_length=5, random_seed=1)
mts = msprime.sim_mutations(ts, rate=0.1, random_seed=5)
mts.tables.sites.position
array([0., 1., 2., 4.])
Specifying discrete_genome=False places mutations at floating point positions
continuously along the genome.
mts = msprime.sim_mutations(ts, rate=0.1, random_seed=5, discrete_genome=False)
mts.tables.sites.position
array([0.44910517, 1.03359577, 1.37043233, 1.98368303, 2.07117512,
2.20654612, 4.04140843])
Note
Using discrete_genome=False means that the mutation model will conform
to the classic infinite sites assumption, where each mutation in the simulation
occurs at a new site.
Restricting time span#
The time range where mutations can be placed is specified using the start_time
and end_time parameters. For instance, the following only allows mutations to occur
earlier than time 1 in the tree:
ts = msprime.sim_ancestry(2, random_seed=1)
mts = msprime.sim_mutations(ts, rate=2, start_time=1, random_seed=1)
mts.tables.mutations.time
array([2.43665171, 2.36231214, 1.89044463, 1.75278168, 1.5317962 ,
1.29553628, 1.18207318, 1.14345689])
Note, however, that the child node of the edge where the mutation occurred can be younger
than start_time.
mts.tables.nodes.time[mts.tables.mutations.node]
array([0. , 1.9775205 , 0. , 0. , 0. ,
0. , 0.17986861, 0. ])
It is also possible to use multiple calls of sim_mutations() with start_time
and end_time specified to simulate differing mutation rates at different
periods of time. For instance, the following code simulates mutations at a low rate
prior to time 1 and at a higher rate more recently.
ts = msprime.sim_ancestry(2, random_seed=1)
mts = msprime.sim_mutations(ts, rate=0.1, start_time=1, random_seed=1)
print(mts.tables.mutations.time)
mts = msprime.sim_mutations(mts, rate=4, end_time=1, random_seed=1)
print(mts.tables.mutations.time)
[1.29553628 1.15674901]
[1.29553628 1.15674901 0.96826157 0.90004028 0.80074457 0.72974006
0.69232262 0.53881673 0.41919452 0.39676747 0.31342418 0.20233004
0.19810148 0.05438014 0.02639678 0.01660881]
As explained in the following section, reversing the order of these two lines will result in an error, as older mutations must be added first.
Silent mutations#
Some of these mutation models produce silent mutations,
that do not change the allelic state.
For instance, here are all the mutations in a small simulation
using the HKY:
def count_transitions(ts, alleles):
counts = np.zeros((len(alleles), len(alleles)), dtype='int')
for s in ts.sites():
aa = s.ancestral_state
for m in s.mutations:
pa = aa
da = m.derived_state
if m.parent != tskit.NULL:
pa = ts.mutation(m.parent).derived_state
counts[alleles.index(pa), alleles.index(da)] += 1
print("\t", "\t".join(alleles))
for j, a in enumerate(alleles):
print(f"{a}\t", "\t".join(map(str, counts[j])))
model = msprime.HKY(kappa=0.75, equilibrium_frequencies=[0.2, 0.3, 0.3, 0.2])
ts = msprime.sim_ancestry(
5, random_seed=1, sequence_length=1e7, recombination_rate=1e-8,
population_size=1000)
mts = msprime.sim_mutations(ts, rate=1e-8, model=model, random_seed=1)
count_transitions(mts, model.alleles)
A C G T
A 0 89 90 74
C 102 36 148 63
G 71 165 39 94
T 60 62 89 0
There are a moderate but small number of C->C and G->G mutations. This is because under the HKY model with these parameters, the mutation rates for C and G is less than that of A and T. However, msprime puts down mutations on the trees at constant rate; and so to make the mutation process correct, some of these “mutations” are chosen to be silent. See Parameterisation of Matrix Mutation Models for more details on how this works.
Such silent mutations might be surprising, but they are harmless:
they do not affect summary statistics
(e.g., tskit.TreeSequence.diversity())
or genotypes in any way.
In fact, leaving them in makes msprime’s mutation process more robust:
see Silent mutations and state-independence for details.
To demonstrate insensitivity to these silent mutations, let’s compute the number of segregating sites for the mutated tree sequence above. Here’s how many sites it has mutations at:
print(f"The tree sequence has {mts.num_sites} sites with mutations.")
The tree sequence has 1182 sites with mutations.
So, we might expect the total number of segregating sites to be 1182.
However, some are silent, and subtracting the number of these gets the same answer as
tskit.TreeSequence.segregating_sites():
num_silent = 0
for s in mts.sites():
for m in s.mutations:
pa = s.ancestral_state
if m.parent != tskit.NULL:
pa = mts.mutation(m.parent).derived_state
if pa == m.derived_state:
num_silent += 1
segsites = mts.segregating_sites(span_normalise=False)
print(f"The tree sequence has {num_silent} silent mutations,\n"
f"and {segsites} segregating sites.")
The tree sequence has 75 silent mutations,
and 1107.0 segregating sites.
Indeed, 1182 - 75 = 1107.
Existing mutations#
When you add mutations to a tree sequence which already contains them, the keep parameter
controls whether existing mutations are kept or discarded (the default is keep=True).
For instance, in final code block in Restricting time span, mutations were
progressively added to a simulated tree sequence, beginning with the oldest time period.
This could also be used to add mutations with different mutation models to different segments
of the genome.
While it is more natural to add younger mutations to a tree sequence which already contains older mutations, you can also add mutations ancestral to existing mutations, as in the following code block:
ts = msprime.sim_ancestry(5, random_seed=1)
mts = msprime.sim_mutations(ts, rate=1, random_seed=1)
mmts = msprime.sim_mutations(mts, rate=0.1, random_seed=5)
print(f"Before: {mts.num_mutations} mutations.\n"
f"After: {mmts.num_mutations} mutations.")
Before: 4 mutations.
After: 6 mutations.
This might be done, for instance, if a tree sequence is the result of a forwards simulation that has non-neutral variation, and you’d like to add neutral mutations.
Silent mutations and state-independence#
Although it is possible to add new mutations ancestrally to
existing mutations, doing so can produce confusing situations.
For instance, new mutations added to an already mutated site
will not assign a new ancestral state: for instance, with the
PAM of amino acid mutation,
if a site has ancestral state V and a mutation with derived state I,
and a new mutation is added ancestral to the existing one,
the derived state of the new mutation will be randomly assigned
(rather than being V as you might expect).
This can lead to unlikely or even impossible situations:
the new mutation in this example might be a G,
since mutations from V to G and V to I are both reasonably likely.
However, a mutation from G to I is impossible under this model,
and we now have the chain V->G->I
(the chain is possible under the BLOSUM62, but unlikely).
In practice this is more confusing than concerning,
since it can only happen when the same site is mutated more than once,
which affects only a small proportion of sites.
The situation above occurred because the probability of mutating to I
was very different depending on the initial state.
However, if derived alleles are chosen in a way independent of the previous state,
then adding mutations at rate \(\alpha\)
and then adding mutations at rate \(\beta\)
is equivalent to adding mutations once, at rate \(\alpha + \beta\).
A mutation model has this property if rows of its transition matrix are the same,
and is called state independent (or, parent independent).
For instance, mutations under the JC69
choose any derived allele with equal probability.
This means that the result of a mutation can be chosen without knowing
what the previous state at that site was (“state independence”),
which implies that adding new mutations above a given mutation does not affect
the probability of that mutation occurring.
However, this is only true if “any derived allele” includes the previous allele,
i.e., if we include silent mutations.
The default Jukes-Cantor model will mutate an A to either a C, G, or T
with equal probability, which we can check by looking at the transition matrix,
whose rows give the probability that each allele mutates into each other allele
(see Matrix Mutation Models for more):
jc69 = msprime.JC69()
jc69.transition_matrix
array([[0. , 0.33333333, 0.33333333, 0.33333333],
[0.33333333, 0. , 0.33333333, 0.33333333],
[0.33333333, 0.33333333, 0. , 0.33333333],
[0.33333333, 0.33333333, 0.33333333, 0. ]])
We can check that this does not produce any silent mutations:
rate = 1.5e-3
ts = msprime.sim_ancestry(5, random_seed=5, sequence_length=1e6)
mts = msprime.sim_mutations(ts, rate=rate, model=jc69, random_seed=7)
count_transitions(mts, jc69.alleles)
A C G T
A 0 1133 1137 1175
C 1116 0 1090 1087
G 1138 1121 0 1172
T 1142 1133 1131 0
Although this model does not include silent mutations,
applying it more than once could produce some -
for instance, if one mutation with derived state C is inserted
above an existing mutation with the same derived state.
To make it state-independent, we have to choose the derived state
uniformly from all nucleotides:
pi_jc69 = msprime.JC69(state_independent=True)
pi_jc69.transition_matrix
array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]])
With this change, mutating twice with JC69
is equivalent to mutating once with rate equal to the sum of the rates.
In other words, these two operations are equivalent:
alpha = 0.4 * rate
beta = 0.6 * rate
# mutate once:
mts1 = msprime.sim_mutations(ts, rate=alpha + beta, model=pi_jc69, random_seed=7)
print("Mutated once:")
count_transitions(mts1, pi_jc69.alleles)
# or, mutate twice:
mts2 = msprime.sim_mutations(ts, rate=alpha, model=pi_jc69, random_seed=7)
mts2 = msprime.sim_mutations(mts2, rate=beta, model=pi_jc69, random_seed=8)
print("Mutated twice:")
count_transitions(mts2, pi_jc69.alleles)
Mutated once:
A C G T
A 832 863 890 860
C 850 823 802 815
G 865 833 860 877
T 853 850 846 856
Mutated twice:
A C G T
A 849 838 845 847
C 840 883 835 823
G 827 885 840 835
T 868 841 852 851
These are very similar - any differences are due to statistical noise.
However, now 25% of the mutations are silent.
These silent mutations are harmless, and will not affect most things at all.
However, they do count as mutations, and so including them decreases the
effective mutation rate.
Above, we produced mts by mutating with the default Jukes-Cantor model
at rate 1.5. Here, we produced mts1 (and mts2) using Jukes-Cantor
but with 25% of the mutations silent.
This means that to produce an set of mutations equivalent to mts
that includes silent mutations, we need to use the state-independent
Jukes-Cantor model with rate \(1/(1-0.25) = 4/3\) times higher:
mts_with_silent = msprime.sim_mutations(ts, rate=rate * 4/3, model=pi_jc69, random_seed=12)
count_transitions(mts_with_silent, pi_jc69.alleles)
A C G T
A 1134 1124 1104 1226
C 1070 1040 1185 1153
G 1175 1106 1072 1118
T 1086 1153 1117 1113
Note that the offdiagonal counts are similar to what we saw above for mts -
again, any differences are due to statistical noise.
Another way to see this is that nucleotide diversity is similar for mts and mts_with_silent,
but is only 75% as big for mts1:
print(f"Nucleotide diversity for default JC69 with rate {rate}: {mts.diversity():.4f}")
print(f" state-independent JC69 with rate {rate}: {mts1.diversity():.4f}")
print(f" state-independent JC69 with rate {rate * 4/3}: {mts_with_silent.diversity():.4f}")
Nucleotide diversity for default JC69 with rate 0.0015: 0.0053
state-independent JC69 with rate 0.0015: 0.0039
state-independent JC69 with rate 0.002: 0.0053
Here’s the takeaways from this section:
Attention
If you’re going to add mutations to the same tree sequence more than once, you should use the
state_independentmutation models (or carefully consider the consequences).If you use a state-independent model, you need to make your mutation rate higher, to account for the silent mutations. See Adjusting mutation rates for silent mutations for more details.
Models#
Mutation models are specified using the model parameter to
sim_mutations(). This parameter can either take the form of a
string describing the model (e.g. model="jc69") or an instance of a
model definition class (e.g model=msprime.JC69()).
Here are the available models; they are documented in more detail below.
BinaryMutationModel: Basic binary mutation model with two flip-flopping alleles: “0” and “1”.JC69: Jukes & Cantor model (‘69), equal probability of transitions between nucleotidesHKY: Hasegawa, Kishino & Yano model (‘85), different probabilities for transitions and transversionsF84: Felsenstein model (‘84), different probabilities for transitions and transversionsGTR: The Generalised Time-Reversible nucleotide mutation model, a general parameterisation of a time-reversible mutation processBLOSUM62: The BLOSUM62 model of time-reversible amino acid mutationPAM: The PAM model of time-reversible amino acid mutationMatrixMutationModel: Superclass of the specific mutation models with a finite set of statesSMM: Stepwise mutation model for microsatellite repeat copy number. Ohta and Kimura (‘78)TPM: Two-phase mutation model for microsatellite repeat copy number. DiRienzo et al. (‘94)EL2: Two-phase mutation model, equal rate, linear bias model for microsatellite repeat copy number. Garza et al. (‘95)InfiniteAlleles: A generic infinite-alleles mutation modelSLiMMutationModel: An infinite-alleles model of mutation producing SLiM-style mutations
Matrix Mutation Models#
These classes are defined by an alphabet of possible alleles (alleles); an array of
probabilities that determines how likely each allele is to be the root or ancestral
allele (root_distribution); and a transition_matrix specifying the probabilities
with which a given mutation changes each allele into each other allele.
Each class generates particular values for these parameters to create the specific model.
For your own custom model these parameters can be set using
msprime.MatrixMutationModel. For more detail about how mutations are simulated
in these models see Parameterisation of Matrix Mutation Models.
Mutation Matrix Models Details#
Mutation matrix models are specified by three things: an alphabet,
a root distribution, and a transition matrix.
These leave one free parameter: an overall mutation rate,
specified by the mutation rate in the call to sim_mutations().
Concisely,
the underlying model of mutation is a continuous-time Markov chain on the alphabet,
started by a draw from root_distribution, and
with instantaneous transition rate from i to j that is equal to
rate multiplied by transition_matrix[i,j].
The root distribution and every row in the transition_matrix
must give probabilities, i.e., they must be nonnegative numbers summing to 1.
For the precise interpretation of these parameters
(especially when the transition matrix has nonzero entries on the diagonal)
see Parameterisation of Matrix Mutation Models.
You can define your own, but you probably don’t need to:
there are several mutation matrix models already implemented in msprime,
using binary (0/1), nucleotide, or amino acid alphabets:
Defining your own finite-sites model#
If you want to define your own MatrixMutationModel, you have a good
deal of freedom. For instance, here’s a “decomposition/growth/disturbance”
mutation model, where the only possible transitions are 🎄 to 🔥, 🔥 to 💩, and
💩 to 🎄, with the first transition happening at one-fifth the rate of the
other two:
alleles = ["💩", "🎄", "🔥"]
model = msprime.MatrixMutationModel(
alleles,
root_distribution = [1.0, 0.0, 0.0],
transition_matrix = [[0.0, 1.0, 0.0],
[0.0, 0.8, 0.2],
[1.0, 0.0, 0.0]]
)
rate = 2
ts = msprime.sim_ancestry(6, population_size=10, random_seed=2, sequence_length=7)
mts = msprime.sim_mutations(ts, rate=rate, random_seed=1, model=model)
We have simulated from this model at rate 2, so the overall rate of mutation from 💩 to 🎄 and 🔥 to 💩 is 2, and from 🎄 to 🔥 is \(2 \times 0.2 = 0.4\). As a result, roughly 5/7th of the states will be 🎄, with the remainder divided evenly between 💩 and 🔥. Here is the resulting “genotype matrix”:
for v in mts.variants():
print("".join(v.alleles[k] for k in v.genotypes))
🔥🎄🎄🎄💩🎄🎄🎄🎄🎄🎄🎄
💩💩💩🎄🎄🎄🎄💩🎄🎄🎄🎄
🎄🎄🔥🔥💩🎄🎄🎄🎄🎄🎄🎄
🎄🎄💩🔥🎄🎄🎄🎄💩💩🔥💩
💩🎄🎄🎄🔥🎄🎄🎄🎄🎄🔥🎄
🎄🎄🎄🎄🎄🎄🎄🎄🎄🎄🎄🎄
💩🎄🎄🎄🎄💩🎄🎄🎄💩🎄💩
Parameterisation of Matrix Mutation Models#
To interpret the root_distribution and transition_matrix parameters,
it helps to know how the underlying mutational process is implemented.
First, mutations are placed on the tree,
with a mean density equal to the rate, per unit of time and sequence length.
If discrete_genome=False then this is an infinite-sites model,
so each mutation occurs at a distinct position along the genome.
If discrete_genome=True (the default setting) then at each integer position,
each branch of the tree at that position gets a Poisson number of mutations
with mean equal to rate multiplied by the length of the branch.
Next, each site that has a mutation is assigned an ancestral state,
i.e., the allele at the root of the tree at that position,
by drawing an allele from the probabilities in the root_distribution.
Now, each mutation is examined, moving down the tree,
and a derived state is chosen using the probabilities given in the
row of the transition_matrix that corresponds to the “parental state”,
i.e., the allele that this mutation will replace.
Importantly, the mutation is recorded even if the chosen allele is the same
as the parental allele - so, if the diagonal of the transition matrix
contains nonzero entries, then the mutated tree sequence will
(probably) contain silent mutations.
Some facts about Markov chains are useful to interpret the statistics
of these mutation models. First, suppose we have tabulated all mutations, and so
for each pair of alleles \(i\) and \(j\) we have the proportion of mutations
that caused an \(i \to j\) change. If allele \(i\) mutates to a different allele,
the chance it mutates to allele \(j\) is proportional to transition_matrix[i,j] but
excluding the diagonal (no-change) entry, so is equal to
transition_matrix[i,j] / (1 - transition_matrix[i,i]).
Second, suppose that an ancestor carries allele \(i\) at a given position.
The probability \(P(t)\) that her descendant some time \(t\) in the future
carries allele \(j\) can be found using the scaled
infinitesimal rate matrix of
the Markov chain, \(Q\), and taking its matrix exponential:
import scipy
Q = model.transition_matrix - np.eye(len(model.alleles))
t = 0.1 # time
scaled_Q = t * rate * Q
Pt = scipy.linalg.expm(scaled_Q)
print("P(t) = probs of allele change along a branch of length", t)
print()
print(" ---- End state ----")
print(" ".join(f"{s:>6}" for s in model.alleles))
for i, s in enumerate(model.alleles):
print(f"{s} " + " ".join(f"{Pt[i,j]:.5f}" for j in range(len(model.alleles))))
P(t) = probs of allele change along a branch of length 0.1
---- End state ----
💩 🎄 🔥
💩 0.81896 0.17759 0.00346
🎄 0.00346 0.96103 0.03552
🔥 0.16376 0.01728 0.81896
If the top of a branch of length \(t\) has allele \(i\),
the bottom of the branch has allele \(j\) with probability Pt[i,j]. Note that
these values are sometimes called the “transition probabilities” for a branch, and
therefore you may see the matrix \(P(t)\) also being referred to as a
“transition matrix”; this should not be confused with the probabilities of a single
mutation resulting in each allele type, as specified via the transition_matrix
parameter and stored under that name as an attribute of the underlying
msprime.MatrixMutationModel.
Adjusting mutation rates for silent mutations#
As discussed in Silent mutations, matrix mutation models can insert silent mutations, which may make it difficult to set the mutation rate appropriately, since by “mutation rate” we mean the rate of appearance of mutations that change the allelic state. However, the “mutation rate” is not in fact a single value: it depends on context, as some alleles may tend to mutate more than others.
As an example of how to appropriately adjust the mutation rate to produce a given expected diversity, take the following somewhat contrived problem. Suppose we generate a tree sequence of 1000 samples of 10Mb from a population of size 1,000, which has mutations generated under the HKY model with \(\kappa = 0.75\) and equilibrium frequencies \(\pi = [0.1, 0.2, 0.3, 0.4]\). We’d like to choose the mutation rate \(\mu\) so that the mean genetic diversity is equal to 0.001. If this was equal to the usual \(\theta = 4Nu\), we’d need a “mutation rate” of \(u = 2.5 \times 10^{-7}\), so we know we’ll need a number slightly higher than that.
To do this, let’s figure out the mean rate of appearance of silent mutations. We know that (a) the rate of appearance of silent mutations per nucleotide is given by \(\mu\) times the diagonal of the transition matrix, and (b) the equilibrium frequency of the four nucleotides is given by \(\pi\). Multiplying these together and adding them up gives us the expected proportion of mutations that are silent. Now, writing that we want \(u\) to equal \(\mu\) times one minus the this proportion, we get \(2.5 \times 10^{-7} = \mu (1 - \sum_i \pi_i P_{ii})\), so solving for \(\mu\) gives us:
pi = np.array([0.1, 0.2, 0.3, 0.4])
hky = msprime.HKY(kappa=0.75, equilibrium_frequencies=pi)
P = hky.transition_matrix
u = 2.5e-7
mu = u / (1 - np.sum(pi * np.diag(P)))
print(f"Mutation rate should be increased by a factor of {mu/u:.2f}.")
Mutation rate should be increased by a factor of 1.28.
Now, let’s verify we get the nucleotide diversity we were aiming for:
ts = msprime.sim_ancestry(1000, population_size=1000, sequence_length=1e7, recombination_rate=1e-8, random_seed=5)
mts = msprime.sim_mutations(ts, rate=mu, model=hky, random_seed=27)
theta = mts.diversity()
print(f"Genetic diversity: {theta}.")
Genetic diversity: 0.0010836445272138172.
That’s pretty close to 0.001! The difference is within statistical error.
Microsatellite Mutation Models#
We have implemented a number of mutational models that are commonly used to model the evolution of microsatellite repeats. The basic idea here is that the number of copies of a given repeat is tracked, and its evolution over time subject to one of a number of potential biases.
Consider the Combined DNA Index System
(CODIS), a US National database
of genotypes maintained by the justice system for use in forensic DNA analysis.
The CODIS system relies on 20 core microsatellite loci, that are unlinked across
the human genome. Let’s simulate a sample of 5 individuals at 20 unlinked loci,
and then apply the SMM model to the sample.
After running the simulation we then examine the variation across the loci, by
iterating through the variants.
Note
The alleles in MicrosatMutationModels such as this represent the
copy number of the repeat, not the actual sequences observed. See below for some basic
techniques for working with this kind of data.
ts = msprime.sim_ancestry(5, random_seed=2, sequence_length=20,
recombination_rate=0.5, population_size=100_000)
model = msprime.SMM(lo=1, hi=10)
mts = msprime.sim_mutations(ts, rate=1e-5, model=model, random_seed=1)
for var in mts.variants():
print("Site at:", var.site.position)
print(" Alleles:", var.alleles)
print(" Genotypes:", var.genotypes)
Site at: 0.0
Alleles: ('5', '6', '7', '8', '4', '3')
Genotypes: [0 4 4 2 2 5 4 0 4 4]
Site at: 1.0
Alleles: ('8', '7')
Genotypes: [0 0 0 0 0 0 0 0 1 0]
Site at: 2.0
Alleles: ('6', '5', '4')
Genotypes: [0 0 1 0 2 1 1 2 1 0]
Site at: 3.0
Alleles: ('2', '3', '1')
Genotypes: [2 0 0 0 0 1 0 1 0 0]
Site at: 4.0
Alleles: ('2', '1', '3')
Genotypes: [0 1 0 1 2 0 0 1 1 0]
Site at: 5.0
Alleles: ('1', '2')
Genotypes: [1 1 0 1 1 1 1 0 0 1]
Site at: 6.0
Alleles: ('7', '8', '9', '10')
Genotypes: [0 0 1 3 0 1 2 2 2 0]
Site at: 7.0
Alleles: ('10', '9', '8')
Genotypes: [0 0 1 0 2 0 1 0 0 1]
Site at: 8.0
Alleles: ('9', '10')
Genotypes: [0 1 0 1 0 0 1 0 0 0]
Site at: 9.0
Alleles: ('7', '8')
Genotypes: [0 0 0 1 0 0 0 0 1 0]
Site at: 10.0
Alleles: ('3', '2', '1', '4')
Genotypes: [0 3 0 0 0 3 3 0 1 0]
Site at: 11.0
Alleles: ('3', '4', '2', '1')
Genotypes: [3 3 1 2 2 1 1 0 1 3]
Site at: 12.0
Alleles: ('3', '2', '1')
Genotypes: [0 1 2 2 1 1 2 1 2 2]
Site at: 13.0
Alleles: ('5', '4', '3', '2', '6', '7', '8', '9')
Genotypes: [2 5 5 5 6 5 7 5 5 6]
Site at: 14.0
Alleles: ('5', '6', '4', '3', '7')
Genotypes: [0 2 1 1 2 0 1 3 4 0]
Site at: 15.0
Alleles: ('2', '1', '3', '4', '5', '6')
Genotypes: [1 5 5 1 3 1 3 1 5 1]
Site at: 16.0
Alleles: ('6', '7', '5', '4')
Genotypes: [1 2 0 3 0 0 2 1 0 1]
Site at: 17.0
Alleles: ('8', '7', '9', '6', '5', '4', '3', '2')
Genotypes: [0 1 5 0 6 0 7 2 0 6]
Site at: 18.0
Alleles: ('2', '1', '3', '4', '5')
Genotypes: [4 1 3 0 4 3 3 4 3 1]
Site at: 19.0
Alleles: ('8', '9', '7', '10')
Genotypes: [1 3 0 3 3 3 3 1 1 3]
Working with copy numbers#
In order to perform some statistical analysis of microsatellite models,
we need a function to convert the output of msprime into something that
we can work with easily. The variation data is returned using the
tskit tskit.TreeSequence.variants() method, which uses an array of
alleles (the different states observed at a site) and an array of
“genotypes”, which are the observations at that site for all of the samples.
Usually, we think of alleles as being nucleotides or amino acids which
are represented as strings. In this case, however, the alleles
represent copy-numbers which are still represented as strings. So,
to get the observed copy numbers, we must convert the alleles
to a numeric type, and obtain the actual observations by
indexing into this array. This is done in the following function:
def copy_number_matrix(ts):
"""
Returns the copy number matrix from the specified tree sequence
simulated under a MicrosatMutationModel.
"""
C = np.zeros((ts.num_sites, ts.num_samples), dtype=int)
for var in ts.variants():
alleles = np.array([int(allele) for allele in var.alleles])
C[var.site.id] = alleles[var.genotypes]
return C
Using this new tool, we can now look at the dependence of the variance in repeat
number on mutation rate under the SMM model. Much has been
written over the years on how to estimate the mutation
rate from the variance in repeat number
(e.g., Zhivotovsky and Feldman, 1995),
so let’s simulate that signal:
from matplotlib import pyplot as plt
rates = np.linspace(1e-2, 1e-4, num=20)
variances = []
ts = msprime.sim_ancestry(100, random_seed=2, sequence_length=1, population_size=100_000)
for r in rates:
mts = msprime.sim_mutations(ts, rate=r, model=msprime.SMM(), random_seed=1)
C = copy_number_matrix(mts)
variances.append(C.var())
plt.plot(rates, variances)
plt.xlabel('Mutation rate')
plt.ylabel('Variance in repeat number');
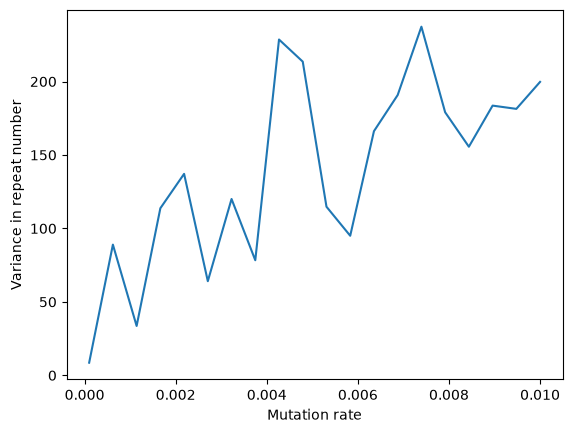
So here we are seeing a clear relationship between the variance in repeat number and mutation rate, as expected. 🔥🔥🔥
A more complicated microsatellite model#
In the 1990s a lot of work went in to describing patterns of
mutation at microsatellite loci, and several models were
put forward describing various biases in expansion vs contraction,
mutistep mutations, and mutation rate biases. The
MicrosatMutationModel implements the general parameterization
of microsatellite mutation models developed in
Sainudiin et al. (2004),
allowing users fine grained control of microsatellite mutation.
One concrete instance of this general model is the equal rate, linear biased, two-phase
mutation model of Garza et al. (1995)
that we have implemented in EL2. Let’s simulate large
samples under this model with different strengths of linear bias,
and compare the distribution of allele sizes we get back.
from matplotlib import pyplot as plt
from scipy import stats
biases = np.logspace(-7, 1, num=9)
ts = msprime.sim_ancestry(
1000, random_seed=2, sequence_length=1, population_size=100_000)
for v in biases:
# these are values of m and u from Sainudiin et al. (2004)
model = msprime.EL2(m=0.01, u=0.68, v=v)
mts = msprime.sim_mutations(ts, rate=1e-3, model=model)
C = copy_number_matrix(mts)
kde = stats.gaussian_kde(C.flatten())
x = np.linspace(2, 51)
plt.plot(x, kde(x), label=f'v={v}')
plt.xlabel('copy number')
plt.ylabel('frequency')
plt.legend()
plt.show();
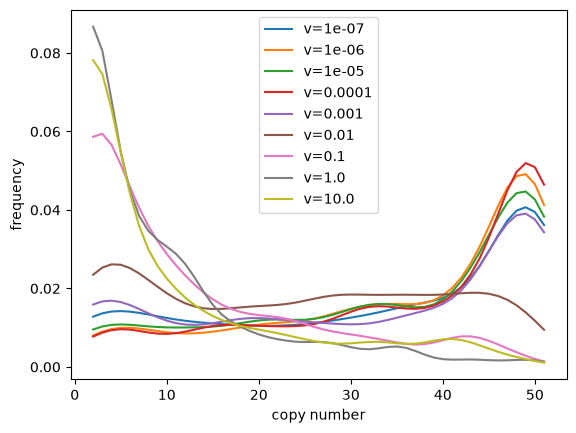
From these simulations we can see that the linear bias parameter v
has a strong effect on the distribution of allele frequencies we
might expect from our model. Care should be taken when choosing
parameters for your own simulations. Potentially appropriate
values for dinucleotide repeats in humans and chimp could be taken
from Table 2 of Sainudiin et al. (2004),
but we offer no guarantees and your mileage may vary.
Infinite Alleles Mutation Models#
You can also use a model of infinite alleles mutation: where each new mutation produces a unique,
never-before-seen allele. The underlying mutation model just assigns the derived state
to be a new integer every time a new mutation appears.
By default these integers start at zero, but a different starting point can be chosen,
with the start_allele parameter.
It does this globally across all mutations, so that the first assigned allele will be start_allele,
and if n alleles are assigned in total (across ancestral and derived states),
these will be the next n-1 integers.
Many theoretical results are derived based on this mutation model (e.g., Ewens’ sampling formula).
For instance, here we’ll simulate with the infinite alleles model on a single tree, and print the resulting tree, labeling each mutation with its derived state:
ts = msprime.sim_ancestry(6, random_seed=2, sequence_length=1)
model = msprime.InfiniteAlleles()
mts = msprime.sim_mutations(ts, rate=2, random_seed=1, model=model)
t = mts.first()
ml = {m.id: m.derived_state for m in mts.mutations()}
SVG(t.draw_svg(mutation_labels=ml, node_labels={}, size=(400, 300)))

Apparently, there were 20 mutations at this site, but the alleles present in the population are “13” (in five copies), “17” (in two copies), and one copy each of “14”, “15”, “19”, and “20”. Note that all other mutations on the tree are not observed in the population as they have been are “overwritten” by subsequent mutations.
Warning
Neither this nor the next infinite alleles mutation model check to see if the alleles they produce already exist at the mutated sites. So, if you are using these models to add mutations to an already-mutated tree sequence, it is up to you to set the starting allele appropriately, and to make sure the results make sense!
SLiM mutations#
A special class of infinite alleles model is provided for use with SLiM,
to agree with the underlying mutation model in SLiM.
As with the InfiniteAlleles model, it assigns each new mutation a unique integer,
by keeping track of the next_id and incrementing it each time a new mutation appears.
This differs from the InfiniteAlleles because mutations
in SLiM can “stack”: new mutations can add to the existing state, rather than
replacing the previous state. So, derived states are comma-separated lists of
mutation IDs, and the ancestral state is always the empty string. For instance,
if a new mutation with ID 5 occurs at a site, and then later another mutation
appears with ID 64, the sequence of alleles moving along this line of descent
would be "", then "5", and finally "5,64". Furthermore, the mutation
model adds SLiM metadata to each mutation, which records, among other things,
the SLiM mutation type of each mutation, and the selection coefficient (which
is always 0.0, since adding mutations in this way only makes sense if they are
neutral). For this reason, the model has one required parameter: the type
of the mutation, a nonnegative integer. If, for instance, you specify
type=1, then the mutations in SLiM will be of type m1. For more
information, and for how to modify the metadata (e.g., changing the selection
coefficients), see
the pyslim documentation.
For instance,
model = msprime.SLiMMutationModel(type=1)
mts = msprime.sim_mutations(
ts, rate=1, random_seed=1, model=model)
t = mts.first()
ml = {m.id: m.derived_state for m in mts.mutations()}
SVG(t.draw_svg(mutation_labels=ml, node_labels={}, size=(400, 300)))

These resulting alleles show how derived states are built.
The behaviour of this mutation model when used to add mutations to a previously mutated tree sequence can be subtle. Let’s look at a simple example. Here, we first lay down mutations of type 1, starting from ID 0:
model_1 = msprime.SLiMMutationModel(type=1)
mts_1 = msprime.sim_mutations(ts, rate=0.5, random_seed=2, model=model_1)
t = mts_1.first()
ml = {m.id: m.derived_state for m in mts_1.mutations()}
SVG(t.draw_svg(mutation_labels=ml, node_labels={}, size=(400, 300)))

Next, we lay down mutations of type 2. These we assign starting from ID 100, to make it easy to see which are which: in general just need to make sure that we start at an ID greater than any previously assigned.
model_2 = msprime.SLiMMutationModel(type=2, next_id=100)
mts = msprime.sim_mutations(
mts_1, rate=0.5, random_seed=3, model=model_2, keep=True)
t = mts.first()
ml = {m.id: m.derived_state for m in mts.mutations()}
SVG(t.draw_svg(mutation_labels=ml, node_labels={}, size=(400, 300)))

Note what has happened here: on the top branch on the right side of the tree,
with the first model we added two mutations: first a mutation with ID 0,
then a mutation with ID 3.
Then, with the second model, we added two more mutations to this same branch,
with IDs 100 and 102, between these two mutations.
These were added to mutation 0, obtaining alleles 0,100 and 0,100,102.
But then, moving down the branch, we come upon the mutation with ID 3.
This was already present in the tree sequence, so its derived state is not modified:
0,3. We can rationalise this, post-hoc, by saying that the type 1 mutation 3
has “erased” the type 2 mutations 100 and 102.
If you want a different arrangement,
you can go back and edit the derived states (and metadata) as you like.