Publications on new tskit functionality
Working with genetic relatedness
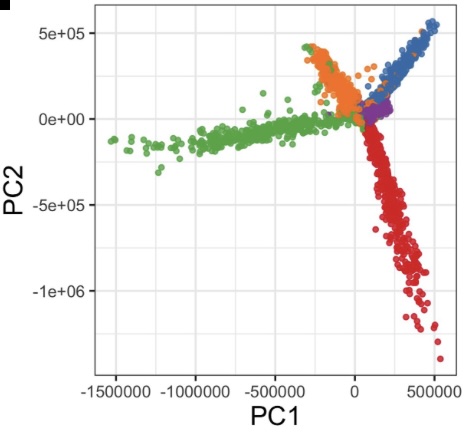
Brieuc Lehman at UCL and others in the tskit developer community have introduced a method to use the tree sequence encoding to efficiently multiply the genetic relatedness matrix (GRM) by a vector, even for huge sample sizes. This is a foundation for many other potential methods. As an example, it is used to implement fast principle component analysis (PCA) on ARGs and other tree sequences, scalable to very large sample sizes (image; left).
The approach is described in Lehmann et al. (2025) On ARGs, pedigrees, and genetic relatedness matrices, Genetics: iyaf219 doi: 10.1093/genetics/iyaf219.
The new methods are available as ts.pca() and ts.genetic_relatedness_vector(). As of June 2026, we also have a PCA tutorial.
Extending haplotypes
Halley Fritz at Oregon and colleagues have a paper describing the new ts.extend_haplotypes() method. This discusses how non-coalescent segments of nodes in an ancestral recombination graph (ARG) are important, shows how to infer them, and discusses why this can make tree sequence encodings of ARGs more efficient. also describes haplotype-aware methods to compare tree sequences, implemented in the tscompare library
The paper is in the same journal edition: Fritze et al. (2025) A forest is more than its trees: haplotypes and ancestral recombination graphs, Genetics: iyaf198 doi: 10.1093/genetics/iyaf198.